
Fat Thinking and Economies of Variety
Leak before failure is a fascinating engineering principle, used in the design of things like nuclear power plants. The idea, loosely stated, is that things should fail in easily recoverable non-critical ways (such as leaks) before they fail in catastrophic ways (such as explosions or meltdowns). This means that various components and subsystems are designed with varying margins of safety, so that they fail at different times, under different conditions, in ways that help you prevent bigger disasters using smaller ones.
 So for example, if pressure in a pipe gets too high, a valve should fail, and alert you to the fact that something is making pressure rise above the normal range, allowing you to figure it out and fix it before it gets so high that a boiler explosion scenario is triggered. Unlike canary-in-the-coalmine systems or fault monitoring/recovery systems, leak-before-failure systems have failure robustnesses designed organically into operating components, rather than being bolted on in the form of failure management systems.
Leak-before-failure is more than just a clever idea restricted to safety issues. Understood in suitably general terms, it provides an illuminating perspective on how companies scale.
Learning as Inefficiency
If you stop to think about it for a moment, leak-before-failure is a type of intrinsic inefficiency where monitoring and fault-detection systems are extrinsic overheads. A leak-before-failure design implies that some parts of the system are over-designed relative to others, with respect to the nominal operating envelope of the system. In a chain with a clear weakest link, the other links can be thought of as having been over-designed to varying degrees.
In the simplest case, leak-before-failure is like deliberately designing a chain with a calibrated amount of non-uniformity in the links, to control where the weakest link lies,. You can imagine, for instance, a chain with one link being structurally weaker than the rest, so it is the first to break under tensile stress (possibly in a way that decouples the two ends of the chain in a safe way as illustrated below).
So for example, if pressure in a pipe gets too high, a valve should fail, and alert you to the fact that something is making pressure rise above the normal range, allowing you to figure it out and fix it before it gets so high that a boiler explosion scenario is triggered. Unlike canary-in-the-coalmine systems or fault monitoring/recovery systems, leak-before-failure systems have failure robustnesses designed organically into operating components, rather than being bolted on in the form of failure management systems.
Leak-before-failure is more than just a clever idea restricted to safety issues. Understood in suitably general terms, it provides an illuminating perspective on how companies scale.
Learning as Inefficiency
If you stop to think about it for a moment, leak-before-failure is a type of intrinsic inefficiency where monitoring and fault-detection systems are extrinsic overheads. A leak-before-failure design implies that some parts of the system are over-designed relative to others, with respect to the nominal operating envelope of the system. In a chain with a clear weakest link, the other links can be thought of as having been over-designed to varying degrees.
In the simplest case, leak-before-failure is like deliberately designing a chain with a calibrated amount of non-uniformity in the links, to control where the weakest link lies,. You can imagine, for instance, a chain with one link being structurally weaker than the rest, so it is the first to break under tensile stress (possibly in a way that decouples the two ends of the chain in a safe way as illustrated below).
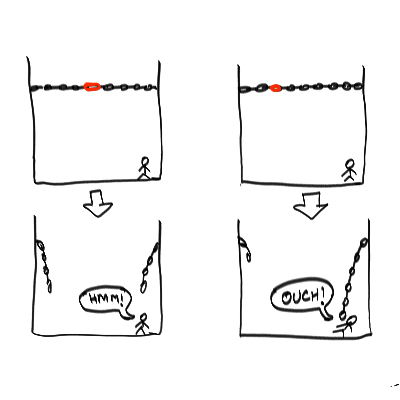 You can imagine, in the same chain, another link that's structurally strong, but made of a steel alloy that rusts the fastest, so if there's a high humidity period, it breaks first. In the two cases, you can investigate the unusual load pattern, or possible failure in the HVAC (heating, ventilation and air conditioning) system.
Failure landscapes designed on the basis of leak-before-failure principles can sometimes do more than detect certain exceptional conditions. They might even prevent higher-risk scenarios by increasing the probability of lower-risk scenarios. One example is what is known as sacrificial protection: using a metal that oxidizes more easily to protect one that oxidizes less easily (magnesium is often used to protect steel pipes if I am remembering my undergrad metallurgy class right).
The opposite of leak-before-failure is another idea in engineering called design optimization, which is based on the exact opposite principle that all parts of a system should fail simultaneously. This is the equivalent of designing a chain with such extraordinarily high uniformity that at a certain stress level, all the links break at once (or what is roughly an equivalent thing, the probability distribution of link failure becomes a uniform distribution, with equal expectation that any link could be the first to break, based on invisible and unmodeled non-uniformities).
Slack and Learning
The inefficiency in a leak-before-failure design can be understood as controlled slack introduced for the purposes of learning and growing through non-catastrophic failure. A way to turn the sharp boundary of the operating regime of an optimized design into a fuzzy, graceful degradation boundary. So leak-before-failure is essentially a formalization and elaboration of the intuition that holding some slack in reserve is necessary for open-ended adaptation and learning. But this slack isn't in the form of reserves of cash, ready for exogeneous "injection" into the right loci. Instead, it is in the form of variation in the levels of over-design in different parts of the system. It is a working reserve, not a waiting reserve.
For those of you who are fans of critical path/theory of constraints methods, you can think of an optimized design as one where the bottleneck is everywhere at once, and every path is a critical path. It is a degenerate state. In the idealized extreme case, the operating regime of the system is a single optimal operating point, with any deviation at all leading to a catastrophic failure of the whole thing.
Mathematically, you get this kind of degeneracy by getting rid of dimensions of design or configuration space you think you don't need. This leads to a state of synchronization in time, and homogeneity in structure and behavior, where you can describe the system with fewer variables. A chain with a uniform type of link needs only one link design description. A chain with non-uniform types of link needs as many varieties as you decide you need. At the extreme end, you get a bunch of unique-snowflake link designs, each of which can fail in somewhat different ways, with each kind of failure teaching you something different. A prototype design thrown together via a process of bricolage in a junkyard is naturally that kind of design, primed for a whole lot of learning.
Leak-before-failure can be understood, in critical-path terms, as moving the bottleneck and critical path to a locus that allows a system to be primed for a particular type of high-value learning. Instead of putting it where you maximize output, utilization, productivity, or any of the other classic "lean" measures of performance.
Or to put it another way, leak-before-failure is about figuring out where to put the fat. Or to put it yet another way, it's about figuring out how to allocate the antifragility budget. Or to put it a third way, it's about designing systems with unique snowflake building blocks. Or to put it a fourth way, it is to swap the sacred and profane values of industrial mass manufacturing. Or to put it a fifth way, it's about designing for a bigger envelope of known and unknown contingencies around the nominal operating regime.
Or to put it in a sixth way, and my favorite way, it's about designing for economies of variety. Learning in open-ended ways gets cheaper with increasing (and nominally unnecessary) diversity, variability and uniqueness in system design.
Note that you sometimes don't need to explicitly know what kind of failure scenario you're designing for. Introducing even random variations in non-critical components that have identical nominal designs is a way to get there (one example of this is the practice, in data centers, of having multiple generations of hardware, especially hard disks, in the architecture)
The fact that you can think of the core idea in so many different ways should tell you that there is no formula for leak-before-failure thinking: it is a kind of creative-play design game which I call fat thinking. To get to economies of scale and scope, you have to think lean. To get to economies of variety on the other hand, you have to think fat.
The Essence of Fat Thinking
If you're familiar with lean thinking in both manufacturing and software, let me pre-empt a potential confusion: setting up a system for leak-before-failure is not the same as agility, in the sense of recovering quickly from failures or learning the right lessons from failure in a time-bound way, or incorporating market signals quickly into business decisions.
Easy way to keep the two distinct: lean thinking is about smart maneuvering, fat thinking is about smart growth.
Leak-before-failure in the broadest sense, is a way to bias an entire system towards open-ended learning in a particular area, while managing the risk of that failure. It is a type of calibrated, directed chaos-monkeying, that actually sacrifices some leanness for growth learning and insurance purposes. If in addition you are able to distribute your slack to drive potentially high-leverage learning in chosen areas, it is also a way to uncover new strategic advantages.
How so? Lean is really defined by two imperatives, both of which fat thinking violates:
You can imagine, in the same chain, another link that's structurally strong, but made of a steel alloy that rusts the fastest, so if there's a high humidity period, it breaks first. In the two cases, you can investigate the unusual load pattern, or possible failure in the HVAC (heating, ventilation and air conditioning) system.
Failure landscapes designed on the basis of leak-before-failure principles can sometimes do more than detect certain exceptional conditions. They might even prevent higher-risk scenarios by increasing the probability of lower-risk scenarios. One example is what is known as sacrificial protection: using a metal that oxidizes more easily to protect one that oxidizes less easily (magnesium is often used to protect steel pipes if I am remembering my undergrad metallurgy class right).
The opposite of leak-before-failure is another idea in engineering called design optimization, which is based on the exact opposite principle that all parts of a system should fail simultaneously. This is the equivalent of designing a chain with such extraordinarily high uniformity that at a certain stress level, all the links break at once (or what is roughly an equivalent thing, the probability distribution of link failure becomes a uniform distribution, with equal expectation that any link could be the first to break, based on invisible and unmodeled non-uniformities).
Slack and Learning
The inefficiency in a leak-before-failure design can be understood as controlled slack introduced for the purposes of learning and growing through non-catastrophic failure. A way to turn the sharp boundary of the operating regime of an optimized design into a fuzzy, graceful degradation boundary. So leak-before-failure is essentially a formalization and elaboration of the intuition that holding some slack in reserve is necessary for open-ended adaptation and learning. But this slack isn't in the form of reserves of cash, ready for exogeneous "injection" into the right loci. Instead, it is in the form of variation in the levels of over-design in different parts of the system. It is a working reserve, not a waiting reserve.
For those of you who are fans of critical path/theory of constraints methods, you can think of an optimized design as one where the bottleneck is everywhere at once, and every path is a critical path. It is a degenerate state. In the idealized extreme case, the operating regime of the system is a single optimal operating point, with any deviation at all leading to a catastrophic failure of the whole thing.
Mathematically, you get this kind of degeneracy by getting rid of dimensions of design or configuration space you think you don't need. This leads to a state of synchronization in time, and homogeneity in structure and behavior, where you can describe the system with fewer variables. A chain with a uniform type of link needs only one link design description. A chain with non-uniform types of link needs as many varieties as you decide you need. At the extreme end, you get a bunch of unique-snowflake link designs, each of which can fail in somewhat different ways, with each kind of failure teaching you something different. A prototype design thrown together via a process of bricolage in a junkyard is naturally that kind of design, primed for a whole lot of learning.
Leak-before-failure can be understood, in critical-path terms, as moving the bottleneck and critical path to a locus that allows a system to be primed for a particular type of high-value learning. Instead of putting it where you maximize output, utilization, productivity, or any of the other classic "lean" measures of performance.
Or to put it another way, leak-before-failure is about figuring out where to put the fat. Or to put it yet another way, it's about figuring out how to allocate the antifragility budget. Or to put it a third way, it's about designing systems with unique snowflake building blocks. Or to put it a fourth way, it is to swap the sacred and profane values of industrial mass manufacturing. Or to put it a fifth way, it's about designing for a bigger envelope of known and unknown contingencies around the nominal operating regime.
Or to put it in a sixth way, and my favorite way, it's about designing for economies of variety. Learning in open-ended ways gets cheaper with increasing (and nominally unnecessary) diversity, variability and uniqueness in system design.
Note that you sometimes don't need to explicitly know what kind of failure scenario you're designing for. Introducing even random variations in non-critical components that have identical nominal designs is a way to get there (one example of this is the practice, in data centers, of having multiple generations of hardware, especially hard disks, in the architecture)
The fact that you can think of the core idea in so many different ways should tell you that there is no formula for leak-before-failure thinking: it is a kind of creative-play design game which I call fat thinking. To get to economies of scale and scope, you have to think lean. To get to economies of variety on the other hand, you have to think fat.
The Essence of Fat Thinking
If you're familiar with lean thinking in both manufacturing and software, let me pre-empt a potential confusion: setting up a system for leak-before-failure is not the same as agility, in the sense of recovering quickly from failures or learning the right lessons from failure in a time-bound way, or incorporating market signals quickly into business decisions.
Easy way to keep the two distinct: lean thinking is about smart maneuvering, fat thinking is about smart growth.
Leak-before-failure in the broadest sense, is a way to bias an entire system towards open-ended learning in a particular area, while managing the risk of that failure. It is a type of calibrated, directed chaos-monkeying, that actually sacrifices some leanness for growth learning and insurance purposes. If in addition you are able to distribute your slack to drive potentially high-leverage learning in chosen areas, it is also a way to uncover new strategic advantages.
How so? Lean is really defined by two imperatives, both of which fat thinking violates:
So for example, if pressure in a pipe gets too high, a valve should fail, and alert you to the fact that something is making pressure rise above the normal range, allowing you to figure it out and fix it before it gets so high that a boiler explosion scenario is triggered. Unlike canary-in-the-coalmine systems or fault monitoring/recovery systems, leak-before-failure systems have failure robustnesses designed organically into operating components, rather than being bolted on in the form of failure management systems.
Leak-before-failure is more than just a clever idea restricted to safety issues. Understood in suitably general terms, it provides an illuminating perspective on how companies scale.
Learning as Inefficiency
If you stop to think about it for a moment, leak-before-failure is a type of intrinsic inefficiency where monitoring and fault-detection systems are extrinsic overheads. A leak-before-failure design implies that some parts of the system are over-designed relative to others, with respect to the nominal operating envelope of the system. In a chain with a clear weakest link, the other links can be thought of as having been over-designed to varying degrees.
In the simplest case, leak-before-failure is like deliberately designing a chain with a calibrated amount of non-uniformity in the links, to control where the weakest link lies,. You can imagine, for instance, a chain with one link being structurally weaker than the rest, so it is the first to break under tensile stress (possibly in a way that decouples the two ends of the chain in a safe way as illustrated below).
You can imagine, in the same chain, another link that's structurally strong, but made of a steel alloy that rusts the fastest, so if there's a high humidity period, it breaks first. In the two cases, you can investigate the unusual load pattern, or possible failure in the HVAC (heating, ventilation and air conditioning) system.
Failure landscapes designed on the basis of leak-before-failure principles can sometimes do more than detect certain exceptional conditions. They might even prevent higher-risk scenarios by increasing the probability of lower-risk scenarios. One example is what is known as sacrificial protection: using a metal that oxidizes more easily to protect one that oxidizes less easily (magnesium is often used to protect steel pipes if I am remembering my undergrad metallurgy class right).
The opposite of leak-before-failure is another idea in engineering called design optimization, which is based on the exact opposite principle that all parts of a system should fail simultaneously. This is the equivalent of designing a chain with such extraordinarily high uniformity that at a certain stress level, all the links break at once (or what is roughly an equivalent thing, the probability distribution of link failure becomes a uniform distribution, with equal expectation that any link could be the first to break, based on invisible and unmodeled non-uniformities).
Slack and Learning
The inefficiency in a leak-before-failure design can be understood as controlled slack introduced for the purposes of learning and growing through non-catastrophic failure. A way to turn the sharp boundary of the operating regime of an optimized design into a fuzzy, graceful degradation boundary. So leak-before-failure is essentially a formalization and elaboration of the intuition that holding some slack in reserve is necessary for open-ended adaptation and learning. But this slack isn't in the form of reserves of cash, ready for exogeneous "injection" into the right loci. Instead, it is in the form of variation in the levels of over-design in different parts of the system. It is a working reserve, not a waiting reserve.
For those of you who are fans of critical path/theory of constraints methods, you can think of an optimized design as one where the bottleneck is everywhere at once, and every path is a critical path. It is a degenerate state. In the idealized extreme case, the operating regime of the system is a single optimal operating point, with any deviation at all leading to a catastrophic failure of the whole thing.
Mathematically, you get this kind of degeneracy by getting rid of dimensions of design or configuration space you think you don't need. This leads to a state of synchronization in time, and homogeneity in structure and behavior, where you can describe the system with fewer variables. A chain with a uniform type of link needs only one link design description. A chain with non-uniform types of link needs as many varieties as you decide you need. At the extreme end, you get a bunch of unique-snowflake link designs, each of which can fail in somewhat different ways, with each kind of failure teaching you something different. A prototype design thrown together via a process of bricolage in a junkyard is naturally that kind of design, primed for a whole lot of learning.
Leak-before-failure can be understood, in critical-path terms, as moving the bottleneck and critical path to a locus that allows a system to be primed for a particular type of high-value learning. Instead of putting it where you maximize output, utilization, productivity, or any of the other classic "lean" measures of performance.
Or to put it another way, leak-before-failure is about figuring out where to put the fat. Or to put it yet another way, it's about figuring out how to allocate the antifragility budget. Or to put it a third way, it's about designing systems with unique snowflake building blocks. Or to put it a fourth way, it is to swap the sacred and profane values of industrial mass manufacturing. Or to put it a fifth way, it's about designing for a bigger envelope of known and unknown contingencies around the nominal operating regime.
Or to put it in a sixth way, and my favorite way, it's about designing for economies of variety. Learning in open-ended ways gets cheaper with increasing (and nominally unnecessary) diversity, variability and uniqueness in system design.
Note that you sometimes don't need to explicitly know what kind of failure scenario you're designing for. Introducing even random variations in non-critical components that have identical nominal designs is a way to get there (one example of this is the practice, in data centers, of having multiple generations of hardware, especially hard disks, in the architecture)
The fact that you can think of the core idea in so many different ways should tell you that there is no formula for leak-before-failure thinking: it is a kind of creative-play design game which I call fat thinking. To get to economies of scale and scope, you have to think lean. To get to economies of variety on the other hand, you have to think fat.
The Essence of Fat Thinking
If you're familiar with lean thinking in both manufacturing and software, let me pre-empt a potential confusion: setting up a system for leak-before-failure is not the same as agility, in the sense of recovering quickly from failures or learning the right lessons from failure in a time-bound way, or incorporating market signals quickly into business decisions.
Easy way to keep the two distinct: lean thinking is about smart maneuvering, fat thinking is about smart growth.
Leak-before-failure in the broadest sense, is a way to bias an entire system towards open-ended learning in a particular area, while managing the risk of that failure. It is a type of calibrated, directed chaos-monkeying, that actually sacrifices some leanness for growth learning and insurance purposes. If in addition you are able to distribute your slack to drive potentially high-leverage learning in chosen areas, it is also a way to uncover new strategic advantages.
How so? Lean is really defined by two imperatives, both of which fat thinking violates:
- Minimizing the amount of invested capital required to do something (so you need less money locked up in capital assets and inventory)
- Maximizing the rate of return on that invested capital (through, broadly, minimizing downtime, or equivalently, time to recover from failures).
13 Comments
Great post, really got me thinking about some stuff.
1. If we are starting to see the emergence of "hominid companies" (Apple, Google w/ Google X, Amazon, etc.), what is the future of competitive markets? If some large companies have evolved a "brain" and can now effectively pioneer without getting killed, can we create a market where many entities can compete effectively? Or are we on a path towards monopolization in (and across) industries?
2. Before we reach the point of an economy run completely by enlightened, hominid companies, does this framework support audacious Keynsian fiscal policy? The government is usually one of the largest systems within any economy. Also it ostensibly exists for the benefit of society directly (as opposed to indirectly through some mechanism like profit seeking). Does the fat-learning framework support the idea of governments acting as martyr pioneers who are happy to pump large amounts of capital into huge projects and let the learnings accrue to others?
- Reminds me of this video -> https://www.youtube.com/watch?v=Z3tNY4itQyw
3. As someone with some background in finance (although not enough to get rich off of genius bets), bond returns can be used as a metaphor for the returns from fat learning. Usually with bonds, the vast majority of returns comes from the interest on interest, not from the individual bond's cash flows. Same way that most of the returns from fat-learning come from the spillover learnings that happen away from the point of failure, not necessarily the failure itself.
Would love to hear your thoughts.
I will have to return to this post and re-read it for greater profit. The minute I saw "bricolage" I told myself, Venkat is channeling Taleb. Then, antifragility, where to put the fat (Tony), and "Learn or Die" Microeconomics. I couldn't stop smiling. You sir are a master. Kudos.
Mr Rao,
I very much liked your post on "Legibility". Thank you.
Have you read Ludwig von Mises, "Bureaucracy"? I think that would add to the analysis of why states are so bent on "legibility".
It's available gratis on Mises.org
Thank you, and keep writing!
"The Wonderful One Horse Shay" - late 18c poem about a carriage so "perfectly" constructed that no part wore out before any other part (hence it disintegrated at one instant). From Oliver Wendel Holmes father of OWH Jr, famous supreme court justice.
http://holyjoe.org/poetry/holmes1.htm
Ah damn I read that poem decades ago. If I'd recalled it, I'd have mentioned it. Yes, exactly that principle.
this is exactly right. I can confirm as a former reactor operator.
haven't read the whole piece...just the blowoff valve principle is completely spot on.
our reactor was completely safe, and too small to fail.
we used to run drills of simultaneous shootings, earthquakes, spills, etc.
as per 10cfr20 and 10cfr50.
also most of the media hype about spent fuel storage is pretty bullshit.
or at least that's how me & coworkers felt because our reactor was so small.
it is worth noting our director believed that hormesis held for radioactive exposure.
same as high altitude sun exposure from plane flights...or mountain climbing.
wikipedia.org/wiki/Hormesis
abiding principle:
don't put a massive power reactor on an island where it could have an earthquake.
chernobyl's still doing OK.
now it's a nature preserve!
nice place to visit, just don't stay too long.
Did you mean to link http://allthingsd.com/20100317/the-case-for-the-fat-startup/ instead of this blog in the second last paragraph?
On this note, all evolved machines (living ones), contain large amounts of slack, and they are often the points where entirely new features crop up. Excess bones in the skull evolve into inner ear structures. Listening to high pitched sounds evolves into echolocation and so on.
Yes, thanks. Fixed.
Interesting wrinkle. I've been mainly thinking of slack in areas where you want either failover (so redundancy) or a 'failure budget' of multiple failures so it's the leaner parts that fail and evolve. I think what you're pointing out is a different vector of fatness, where failures might suggest new features to evolve towards. So that kind of slack is more like generic slack/stem cells/potential energy/liquid cash reserves.
I've been thinking through the biological analogy more closely, and I made up this speculative idea in another private discussion which could be completely wrong. Maybe you can correct me if so.
--- begin quote from private discussion --
Leaning out a part of a system is actually about turning it into a sensor in part. One of the 40 ways the eye probably evolved is simply some surface cells being more sensitive to light. Then there would be evolutionary advantage to evolving an eyelid to control when that sensor is used. Then there would be an evolutionary advantage to adding an intelligence/decision-making loop on there to control when to open or close the eyelid. So the full lean/fat analysis says the eye is the lean bit, the eyelid is the fat bit, and the brain circuit that controls when you open/close eyes is what drives agility and smart growth.
Interesting thought. I'll have to think more about it but at a certain level the distinction between sensor and control element and intelligence is not that well-defined in natural systems. Any slack can and will be coopted in different ways, "there would be evolutionary advantage to evolving an eyelid to control when that sensor is used" is not how evolution works, it could be that there are nerves around that are not used for something else all the time and when they start being used for this it confers a survival advantage to the critter leading to more copies of it. Fat cells may be primarily used for storing energy, but now that they are there, they will also be used for sequestering fat soluble toxins, or cushioning, or insulation, or hormone production.
Yeah, I get that... I was skipping lightly over a few million steps :D
But you're bringing up a new and perhaps profound point I think: liquidity of a resource is a function of time, not an absolute. We tend to think of a pile of money as a very "liquid" resource and a pile of very specific spare parts as a very "illiquid" resource. But given enough time, all resources are liquid.
In economic terms, money solves the dual-coincidence-of-wants problem via intermediation. But if time is not an issue, then you can wait billions of years for a particular kind of spare resource, like extra bone, to meet a particular kind of adaptive environment, such as one that makes sensitivity to sound a useful thing.
I agree, that's an excellent point "given enough time, all resources are liquid".